알고리즘 개념
주어진 문제를 풀기 위한 명령어들을 단계적으로 나열한 것
- 입출력: 0개 이상의 외부 입력, 1개 이상의 출력
- 명확성: 각 명령은 모호하지 않고 단순 명확해야 함
- 유한성: 한정된 수의 단계를 거친 후에는 반드시 종료해야 함
- 유효성: 모든 명령은 컴퓨터에서 실행 가능해야 함
- 효율성
→ 주어진 문제에 대한 결과를 생성하기 위해 모호하지 않고 간단하며 컴퓨터가 수행 가능한 일련의 유한개의 명령들을 순서적으로 구성한 것
알고리즘 생성 단계
- 설계
- 표현/기술
- 정확성 검증
- 효율성 분석
자료구조와 알고리즘의 관계
- 자료구조: 데이터 사이의 논리적 관계를 표현하고 조직화 하는 방법
- 효율적인 프로그램을 위해 자료구조와 알고리즘을 고려해야함
알고리즘 설계
- 문제와 그에 따른 조건 등이 매우 다양 → 일반적이고 범용의 설계 기법은 없음
분할정복
- 순환적으로 문제를 푸는 방법 → 문제의 입력을 더 이상 나눌 수 없을 때까지 두 개이 상의 작은 문제로 순환적으로 분할하고, 분할된 문제들을 각각 해결한 후 이들의 해를 결합하여 원래 문제의 해를 구하는 하향식 접근 방법
- 분할된 작은 문제는 원래 문제와 동일하고, 입력 크기만 작아짐
- 분할된 작은 문제는 서로 독립적
- 분할정복의 세 단계
- 분할: 주어진 문제를 여러 개의 작은 문제로 분할
- 정복: 작은 문제를 순환적으로 분할. 만약 작은 문제가 더 이상 불할되지 않을 정도로 크기가 충분히 작다면 순환 호출 없이 작은 문제의 해를 구한다
- 결합: 작은 문제에 대해 정복된 해를 결합하여 원래 문제의 해를 구한다
- 퀵 정렬, 합병 정렬, 이진 탐색
동적 프로그래밍(다이나믹 프로그래밍)
- 최적화 문제의 해를 구하기 위한 상향식 접근 방법 → 문제의 크기가 작은 소문제에 대한 해를 구해서 테이블에 저장해 놓고, 이를 이용하여 크기가 보다 큰 문제의 해를 점진적으로 만듦
- 모든 정점 간의 최단 경로를 구하는 플로이드 알고리즘
그리디
- 해를 구하는 일련의 선택 과정마다 전후 단계의 선택과는 상관없이 각 단계에서 가장 최선이라고 여겨지는 국부적인 최적해를 선택해 나가면 결과적으로 전체적인 최적해를 얻을 수 있을 것이라고 희망하는 방법 → 각 단계의 최적해를 통해 전체적인 최적해를 만들어 내지 못할 수 있음
- 적용 범위는 제한적이지만 간단하면서도 강력한 설계법
알고리즘 분석
- 정확성 분석: 유효한 입력이 일정한 시간 내에 정확한 결과를 생성했는가 → 다양한 수학적 기법을 사용한 이론적 증명이 필요
- 효율성 분석: 알고리즘 수행에 필요한 컴퓨터 자원의 양을 측정
- 공간 복잡도: 메모리 양
- 시간 복잡도: 수행 시간
시간 복잡도
- 알고리즘 수행 시간: 컴퓨터에서 실행시켜 완료될 때까지 걸리는 실제 시간 측정 → 컴퓨터의 종류와 속도, 프로그래밍 언어, 프로그램 작성 방법, 컴파일러의 효율성 등에 종속적이므로 일반성 결여
- 알고리즘에서 단위 연산의 수행 횟수를 모두 더한 값
- 입력 크기가 증가하면 수행 시간도 증가 → 단순히 단위 연산의 개수가 아닌 입력 크기의 함수로 표현
- 입력 데이터의 상태에 종속적 → 평균 수행 시간, 최선 수행 시간, 최악 수행 시간
점근 성능
점근 성능입력 크기 n이 충분히 커짐에 따라 결정되는 성능
- 계수 없이 최고차항만을 이용해서 표현
- 수행 시간의 어림값, 수행 시간의 증가 추세 → 알고리즘의 우열
- Big-oh: 어떤 양의 상수 c와 n_0이 존재하여 모든 n ≥ n_0에 대하여 **f(n) ≤ c*g(n)**이면 f(n)=**O(g(n))**이다
- Big-Omega: b어떤 양의 상수 c와 n_0이 존재하여 모든 n ≥ n_0에 대하여 **f(n) ≥ c*g(n)**이면 f(n)=**Ω(g(n))**이다
- Big-theta: 어떤 양의 상수 c와 n_0이 존재하여 모든 n ≥ n_0에 대하여 **c_1g(n) ≤ f(n) ≥ c_2g(n)**이면 f(n)=**Θ(g(n))**이다
- 주요 O-표기 간의 연산 시간의 크기 관계 O(1) < O(logN) < O(n) < O(n*logN) < O(n^2) < O(n^3) < O(2^n)
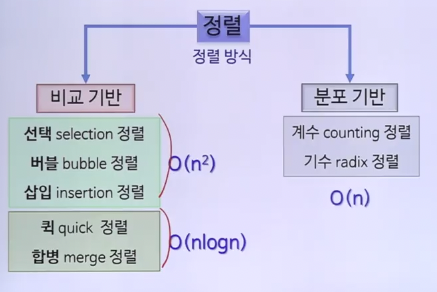
정렬 알고리즘
- 내부 정렬: 모든 데이터를 주기억장치에 적재한 후 정렬하는 방식
- 외부 정렬: 모든 데이터를 주기억장치에 저장할 수 없는 경우, 일부 데이터만 주기억장치에 있고 나머지는 외부기억장치에 저장한 채 정렬하는 방식
선택 정렬
- 주어진 데이터 중에서 가장 작은 값부터 차례대로 선택해서 나열하는 방식
- O(n^2) 언제나 동일한 수행 시간 → 데이터의 입력 상태에 민감하지 않은 수행시간
버블 정렬
- 왼쪽에서부터 모든 인접한 두 데이터를 차례대로 비교하여 왼쪽의 값이 더 큰 경우에는 오른쪽 값과 자리를 바꾸는 과정을 통해 정렬
- 데이터의 입력에 따라 시간 복잡도가 달라짐
- 원하는 순서로 이미 정렬되어 있는 경우 → 최선의 경우 (O(n))
- 역순으로 정렬되어 있는 경우 → 최악의 경우 (O(n^2))
- 선택 정렬에 비해 데이터 교환이 더 많이 발생하므로 선택 정렬보다 비효율적임
삽입 정렬
- 주어진 데이터를 하나씩 뽑은 후, 나열된 데이터들이 항상 정렬된 형태를 가지도록 뽑은 데이터를 바른 위치에 삽입해서 나열하는 방법
- 입력 배열을 정렬 부분과 미정렬 부분으로 구분 → 미정렬 부분의 가장 왼쪽에 있는 데이터를 꺼낸 후, 정렬된 부분에서 제자리르 찾아 삽입하는 과정을 반복
- 데이터의 입력에 따라 시간 복잡도가 달라짐
- 원하는 순서로 이미 정렬되어 있는 경우 → 최선의 경우 (O(n))
- 역순으로 정렬되어 있는 경우 → 최악의 경우 (O(n^2))
퀵 정렬
- 특정 데이터를 기준으로 입력 배열을 두 부분배열로 분할하고, 각 부분배열에 대해서 독립적으로 퀵 정렬을 순환적으로 적용하는 방식 → 평균적으로 가장 좋은 성능의 비교 기반 알고리즘(O(nlogN))
- 피벗(pivot, 분할원소): 두 개의 부분배열로 분할할 때 기준이 되는 데이터 → 보통 주어진 배열의 첫 번째 원소로 지정
- 피벗이 제자리를 잡도록 하여 정렬하는 방식
- 분할정복 방법을 적용한 알고리즘
- 분할: 정렬할 n개 데이터를 피벗을 중심으로 두 개의 부분배열로 분할(O(n))
- 정복: 두 부분배열에 대해 퀵 정렬을 각각 순환적으로 적용하여 두 부분배열을 정렬
- 결합: 필요 없음
- 최선 수행 시간: O(nlogN) → 피벗을 중심으로 항상 동일한 크기의 두 개의 부분배열로 분할되는 경우
- 최악 수행 시간: O(n^2)
- 피벗만 제자리를 잡고 나머지 모든 데이터가 하나의 부분배열로 분할되는 경우
- 피벗이 배열에 항상 최대값 또는 최소값이 되는 경우
- 입력 데이터가 이미 정렬되어 있고, 피벗을 맨 왼쪽 원소로 지정한 경우
- 피벗 선택의 임의성만 보장되면 평균 수행 시간을 보일 가능성이 높음
합병 정렬
동일한 크기의 두 개의 부분배열로 분할하고, 각 부분배열을 순환적으로 정렬한 후, 정렬된 두 부분배열을 합병하여 하나의 정렬된 배열을 만드는 방식(O(nlogN))
- 분할: 정렬할 n개의 데이터를 n/2개의 데이터를 갖는 두 부분배열로 분할
- 정복: 두 부분배열에 대해 합병 정렬을 각각 순환적으로 적용하여 정렬한다
- 결합: 정렬된 두 부분배열을 합병하여 하나의 정렬된 배열을 만듦
탐색
주어진 데이터 집합에서 원하는 값을 가진 데이터를 찾는 작업
순차 탐색
- 리스트 형태로 주어진 데이터를 처음부터 하나씩 차례대로 비교하여 원하는 값을 가진 데이터를 찾는 방법
- 성능(O(n))
- 탐색 실패의 경우: n번 비교
- 탐색 성공의 경우: 최소 1번, 최대 n번, 평균 (n+1)/2번 비교
- 모든 리스트(배열, 연결리스트)에 적용 가능: 데이터가 키 값과 관련해서 아무런 순서 없이 단순하게 연속적으로 저장된 경우에 적합 → 데이터가 정렬되지 않은 경우에 적합
이진 탐색
- 정렬된 입력 배열에 대해서 주어진 데이터를 절반씩 줄여가면서 원하는 데이터를 찾는 방법 → 분할 정복 방법을 적용한 알고리즘
- 탐색 방법: 입력 배열의 가운데 값(A[(a+b)/2])과 탐색키를 비교
- 탐색키 = 배열의 가운데 값 → 탐색 성공(배열의 인덱스(a+b)/2 반환)
- 탐색키 < 배열의 가운데 값 → 이진 탐색(배열의 전반부)
- 탐색키 > 배열의 가운데 값 → 이진 탐색(배열의 후반부)
- 성능(O(logN)): 한 번 탐색할 때마다 탐색 대상이 되는 데이터가 개수 1/2씩 감소
- 데이터가 이미 정렬된 경우에만 적용 가능: 삽입/삭제 연산 시 정렬 상태를 유지하기 위해 데이터의 이동 발생 → 삽입/삭제가 빈번한 응용 분야에는 부적합
이진 탐색 트리
- 이진 트리
- 각 노드의 왼쪽 서브트리에 있는 모든 키 값은 그 노드의 키 값보다 작다
- 각 노드의 오른쪽 서브트리에 있는 모든 키 값은 그 노드의 키 값보다 크다
탐색 연산
루트 노드에서부터 키 값의 비교를 통해 왼쪽/오른쪽 서브트리르 따라 이동하면서 원하는 데이터를 찾음
삽입 연산
삽입할 데이터를 탐색한 후, 탐색이 실패한 위치에 새로운 노드를 자식 노드로 추가 → 탐색 성공 시 삽입 없이 종료
삭제 연산
- 후속자(successor, 계승자) 노드: 어떤 노드의 바로 다음 키 값을 갖는 노드
- 삭제되는 노드의 자식 노드의 개수에 따라 구분해서 처리
- 자식 노드가 없는 경우(리프 노드): 남은 노드의 위치 조절 불필요
- 자식 노드가 하나인 경우: 자식 노드를 삭제되는 노드의 위치로 올리면서 서브트리 전체도 따라 올린다.
- 자식 노드가 두 개인 경우: 후속자 노드를 삭제되는 노드의 위치로 올리고, 후속자 노드의 자식 노드의 개수에 따라 다시 삭제 연산을 처리한다.
성능
키 값의 비교 횟수에 비례 → 트리의 높이가 h라면 O(h)
- 모든 노드의 차수가 2인 경우(리프 노드 제외) → 평균 수행 시간 O(logN)
- 모든 노드의 차수가 1인 경우(리프 노드 제외) → 최악 수행 시간 O(n)
'CS' 카테고리의 다른 글
| [프로그래밍 언어론] 변수와 바인딩 (0) | 2023.12.01 |
|---|---|
| [컴퓨터과학개론] 운영체제 (0) | 2023.11.30 |
| [프로그래밍 언어론] 프로그래밍 언어의 구현 (1) | 2023.11.30 |
| [프로그래밍 언어론] 구문 분석 (0) | 2023.11.23 |
| [프로그래밍 언어론] 구문론과 의미론 (1) | 2023.11.22 |